FPGA秋招学习笔记整理(3)
FPGA autumn recruit study notes (3): Verilog syntax and basic design
FPGA秋招学习笔记整理(3):Verilog语法和基础设计
Verilog 模块的结构
- Verilog HDL的基本设计单元是模块(block),一个模块是由两部分组成的,一部分描述接口;另一部分描述逻辑功能,即定义输入是如何影响输出的。
- 模块中的input、output行说明接口的信号流向,而assign语句、always语句块或者原件例化的方式描述模块的逻辑功能。
- Verilog HDL结构完全嵌在module和endmodule声明语句之间,每个Verilog程序包括4个主要部分:端口定义、I/O说明、信号类型声明和功能描述,下文将会对各个部分进行详细介绍。
/*定义了一个compare比较器。对两比特大小的数a、b进行比较*/
module compare (equal,a,b); //定义模块名为compare,且模块具有三个端口
output equal; //声明输出信号equal
input [1:0] a,b; //声明输入信号a,b
assign equal=(a==b)?1:0; //如果a、b 两个输入信号相等,输出为1。否则为0
endmodule
模块的端口定义
模块的端口声明了模块的输入和输出口。其格式如下:
module module_name(port1,port2,……);
I/O说明
可单独定义输入输出口,也可将其合并在模块声明中一起书写。格式如下:
input port1,port2,……,portN;//共有N个输入端口
output port1,port2,……,portN;//共有N个输出端口
//////或者写在端口声明语句中//////
module module_name(
input InPort1,
input InPort2,
output OutPort1,
output OutPort2
);
信号类型声明
它是说明逻辑描述中所用信号的数据类型及函数声明。其中,对于端口信号的缺省定义类型为wire(连线)型。例如,下面代码是将输出一个端口定义为reg寄存器类型:
reg[7:0] output; // 定义output的数据类型为reg(寄存器)型,位宽为8位
逻辑功能定义
逻辑功能是模块中最重要的部分。有3种方法可在模块中描述逻辑。
- "assign"语句
即使用表达式的方式定义关系,常用于组合逻辑的实现。如:
assign y = (a & (~ s)) | (b & s);//将a与s非的结果和b与s的结果做相或运算,并持续赋值给y
- 元件例化(instantiate)
即调用实例元件或门的方法,且要求元件名唯一。如:
or(y,as,bs) //元件例化或门,并将as与bs做或运算,将结果赋给y
//"always"块语句
//"always"既可用于时序逻辑也可用于组合逻辑,如:
always @(a,b,s) begin //a,b,s为敏感信号列表
if(!s) y = a; //如果s为假,则y=a
else y = b; //否则,y=b
end
需要注意,verilog模块内的各个逻辑功能是并行执行,即如果将上述定义的“assign语句”、元件例化、"always"块放到同一个模块文件中,几个例子将会同时执行,书写的先后次序不会影响逻辑实现的功能,即并发。而在"always"块内,语句却是顺序执行的,代码根据书写的先后顺序进行执行。
基础数据类型
常量
值不能改变的量即为常量
数字
在Verilog HDL中,整型常量即整常数有以下四种进制表示形式:
- 二进制整数(b或B)。
- 十进制整数(d或D)。
- 十六进制整数(h或H)。
- 八进制整数(o或O)。
数字表达方式有以下三种: - <位宽><进制><数字>这是一种全面的描述方式。
- <'><进制><数字>在这种描述方式中,数字的位宽采用缺省位宽(这由具体的机器系统决定,但至少32位)。
- <数字>在这种描述方式中,采用缺省进制十进制。如:6'b100110其中撇号(')之前的数字表示该整型常量的位宽,撇号(')之后紧跟的是表示进制的描述符。
8'b11000101 //位宽8位的二进制数11000101
8'hc5 //位宽8位的十六进制数C5
197 //十进制数197
X和Z值
在数字电路中,x代表不定值,z代表高阻值。在使用case表达式时建议使用这种写法,以提高程序的可读性。如:
4'b10x0 //位宽为4的二进制数,第二位为不定值
4'b101z //位宽为4的二进制数,第一位为高阻态
负数
一个数字可以被定义为负数,只需在位宽表达式前加一个减号,减号必须写在数字定义表达式的最前面。如:-8'd5
下划线
使用下划线可以用来分隔开数的表达以提高程序可读性。如:
16'b1010_1011_1111_1010
参数(parameter)型
用parameter来定义一个标识符代表一个常量,称为符号常量。定义格式如下:
/* parameter 参数名1=表达式,参数名2=表达式, …,参数名n=表达式; */
parameter sel = 8, code = 8'hA3; //定义了常量sel和code
本地参数(localparam)型
用localparam来定义一个标识符代表一个本地私有常量,称为本地符号常量。该常量只可通过内部定义,无法通过外部传入,定义格式如下:
/* localparam 参数名1=表达式,参数名2=表达式, …,参数名n=表达式; */
localparam sel = 8, code = 8'hA3; //定义了常量sel和code
需要注意的是,parameter 可以用于模块间的参数传递,而 localparam 仅用于本模块内使用,不能用于参数传递。 Localparam 多用于状态机状态的定义。
变量
即在程序运行过程中其值可以改变的量、
wire型
网络型变量,wire型数据常用来表示用于以assign关键字指定的组合逻辑信号。wire型信号可以用作任何方程式的输入,也可以用作“assign”语句或实例元件的输出。如:
wire [7:0] in, out; // 定义了两个8位wire型向量in,out
assign out = in; //将in的值持续的赋值给out
reg型
寄存器型变量,寄存器是数据储存单元的抽象,通过赋值语句可以改变寄存器储存的值,reg的初始值为不定值。特别的,reg型只表示被定义的信号将用在“always”块内。如:
reg [7:0] Data; // 定义Data为8位宽的reg型向量
memory型
若干个相同宽度的向量构成数组,reg型数组变量即为memory型变量,即可定义存储器型数据。如:
reg [7:0] Memory [1023:0]; //定义了一个1024字节、字节宽度为8位的名为Memory存储器
Memory[8] = 1; // Memory存储器中的第8个单元赋值为1
运算符与表达式
算数运算符
加(+)减(-)乘(*)除(/)取余(%)。当操作数中有一个不定值X时,整个结果也为不定值X
位运算符
按位取反(~)按位与(&)按位或(|)按位异或(^)按位同或(^~)。
需要注意的一点是两个不同长度的数据进行位运算时,会自动地将两个操作数按右端对齐,位数少的操作数会在高位用0补齐。
举例如下:
A = 5'b11001;
B = 5'b10101;
~ A ; //5'b00110
A & B; //5'b10001
A | B; //5'b11101
A ^ B; //5'b01100
逻辑运算符
逻辑与(&&)逻辑或(||)逻辑非(!)。
举例如下:
!A; //A的非
A&&B //A和B的与
A||B //A和B的或
关系运算符
小于(<)小等于(<=)大于(>)大等于(>=)
在进行关系运算时,如果声明的关系是假,则返回值是0;如果声明的关系是真,则返回值是1;如果某个操作数的值不定,则其结果是模糊的,返回值是不定值。
等式运算符
等于(==)不等于(!=)强等于(===)强不等于(!==)。在普通的等于不等于中,由于操作数中存在不定值X或高阻态Z,结果可能为不定值X。但在强等于强不等于中,要求所有操作数完全一致,结果才是1,否则结果为0,在case表达式中常使用强等于。如:
a = 5'b11x01;
b = 5'b11x01;
a == b //结果为不定值x
a === b //结果为1。
移位运算符
左移运算(<<)右移运算(>>)。
表示把操作数A右移或左移n位,同时用0填补移出的位。如:
A = 5'b11001;
A >> 2; //值为5'b00110,移除的位补0
位拼接运算符
位拼接运算符{ }。用这个运算符可以把两个或多个信号的某些位拼接起来进行运算操作。
当在使用位拼接表达式时不允许存在没有指明位数的信号。这是因为在计算拼接信号的位宽的大小时必需知道其中每个信号的位宽。
{信号1的某几位,信号2的某几位,..,..,信号n的某几位}。如:
input [7:0] A, B;
input Cin;
output [7:0] Sum; // 和输出
output Cout; // 进位输出
assign {Cout, Sum} = A + B + Cin; // 进位与和拼接在一起
位拼接还可以用重复法来简化表达式。如:
{4{w}} //这等同于{w,w,w,w}
{b,{3{a,b}}} //这等同于{b,a,b,a,b,a,b}
//需要注意,在重复表达式中的4和3,务必为常数表达式
条件运算符
信号 = 条件?表达式1:表达式2;
即当条件成立时,信号取表达式1的值,反之取表达式2的值。如:
Out = Sel ?In0 :In1; //二选一选择器,即Sel=1时,Out=In0;Sel=0时,Out=In1
缩减运算符
b = &a; // 等效于b = ((a[0] & a[1]) & a[2]) & a[3];。如:
A = 5'b11001;
&A; //值等于0, 只有A的各位都为1时,其与缩减运算的值才为1
|A; //值等于1, 只有A的各位都为0时,其或缩减运算的值才为0
位切片运算符
- 确切位置的位切片
如果我们已经确定需要将一个多位数值的某几位赋值给另一个变量,可使用:,对其进行位切片
reg [7:0] a = 8'b1010_0101;
reg [3:0] b;
assign b[3:0] = a[7:4] ;//将a的高四位赋值给b
- 不确定位置的位切片
有时候,我们需要切片的位置,并不是一个确定的位置,而是需要将某位输入经过一定运算后得到。但对于:运算符,要求:两边的数字均为一个确定值。故我们需要使用:+或:-运算符进行不确定位置的切片,具体语法如下:
reg [31:0] a =32'haabbccdd;
reg [3:0] b,c;
reg [2:0] byte_addr;//外部输入的byte地址
//从输入地址的byte的第4位开始,向上截取4位赋值给b
assign b[3:0] = a[byte_addr+4 +: 4]
//从输入地址的byte的第7开始,向下截取4位赋值给b
assign b[3:0] = a[byte_addr+7 -: 4]
赋值语句
连续赋值语句
assign为连续赋值语句,它对于对wire型变量进行持续赋值。比如:assign c = a & b;在该赋值语句中,a、b、c三个变量皆为wire型变量,a和b信号的任何变化,都将随时反映到c上来,因此称为连续赋值方式。
过程赋值语句
过程赋值语句用于对寄存器类型(reg)的变量进行赋值,其又分为阻塞和非阻塞两种赋值方式:
非阻塞赋值方式
赋值符号为“<=”,如b <= a;。非阻塞赋值在块结束时才完成赋值操作,即b的值并不是立即就改变的,而要等到该always代码块结束时才将值赋值给目标对象。所以,若是在一个always代码块中对一个变量进行多次非阻塞赋值,则只有最后一次赋值将生效。
阻塞赋值方式
赋值符号为“=”,如b = a; 。阻塞赋值在该语句结束时就完成赋值操作,即b的值在该赋值语句结束后立刻改变。 如果在一个块语句中,有多条阻塞赋值语句,那么在前面的赋值语句没有完成之前,后面的语句就不能执行,就像被阻塞(blocking)了一样,因此称为阻塞赋值方式。
在描述组合逻辑的always块中用阻塞赋值,则综合成组合逻辑的电路结构;在描述时序逻辑的always块中用非阻塞赋值,则综合成时序逻辑的电路结构。
always @( posedge clk ) begin //非阻塞赋值
b<=a; //在always代码块结束时,a的值赋给b,b的值赋给c
c<=b; //赋值过程同时进行更新,实现数据移位操作
end
//////////////////////////////////////////////////////
always @(posedge clk) begin //阻塞赋值
b=a;//首先将a的值赋值给b,覆盖原有b的数据
c=b;//再将b更新后的值赋值给c
end
阻塞与非阻塞赋值使用要点
- 当对时序电路建模时,用非阻塞赋值。
- 当对锁存器电路建模时,用非阻塞赋值。
- 当用always块建立组合逻辑模型时,用阻塞赋值。
- 在同一个always块中建立时序和组合逻辑电路时,用非阻塞赋值。
- 在同一个always块中不要既用非阻塞赋值又用阻塞赋值。
- 不要在一个以上的always块中为同一个变量赋值
块语句
顺序块
块内的语句是按顺序执行的,即只有上面一条语句执行完后下面的语句才能执行。每条语句的延迟时间是相对于前一条语句的仿真时间而言的。直到最后一条语句执行完,程序流程控制才跳出该语句块。格式如下:
parameter d=50; //声明d是一个参数
reg [7:0] r; //声明r是一个8位的寄存器变量
begin //由一系列延迟产生的波形
#d r = 'h35;
#d r = 'hE2;
#d r = 'h00;
#d r = 'hF7;
#d -> end_wave; //触发end_wave事件
end
并行块
块内语句是同时执行的,即程序流程控制一进入到该并行块,块内语句则开始同时并行地执行。块内每条语句的延迟时间是相对于程序流程控制进入到块内时的仿真时间的。
延迟时间是用来给赋值语句提供执行时序的。当按时间时序排序在最后的语句执行完后或一个disable语句执行时,程序流程控制跳出该程序块。
fork
#50 r = 'h35;
#100 r = 'hE2;
#150 r = 'h00;
#200 r = 'hF7;
#250 -> end_wave; //触发事件end_wave.
join
条件语句
条件表达式
信号 = 条件?表达式1 : 表达式2;//当条件成立时,信号取表达式1的值,反之取表达式2的值。
if-else语句
其格式与C语言中if-else语句类似,使用方法有以下3种。系统对表达式的值进行判断,若为0,x,z,按“假”处理;若为“1”,按“真”处理,执行指定语句。 语句可是单句,也可是多句,多句时用“begin-end”语句括起来
if(表达式) 语句1;
//////////////////////////////
if(表达式) 语句1;
else 语句2;
/////////////////////////////
if(表达式1) 语句1;
else if(表达式2) 语句2;
……
else if(表达式n) 语句n;
else 语句n+1;
case语句
当敏感表达式的值为值1时,执行语句1;为值2时,执行语句2;依此类推,如果敏感表达式的值与上面列出的值都不相等的话,则执行default后面的语句。
case语句中,敏感表达式与值1~值n间的比较是一种全等比较,必须保证两者的对应位全等。 在casez语句中,如果分支表达式某些位的值为高阻z,那么对这些位的比较就不予考虑,因此只须关注其他位的比较结果。而在casex语句中,则把这种处理方式进一步扩展到对x的处理,即如果比较的双方有一方的某些位是x或z,那么这些位的比较就都不予考虑。
case中可以有重复的case item,首次匹配的将会被执行。
case语句的使用格式如下:
case(敏感表达式)
值1:语句1; // case分支项
值2:语句2;
……
值n:语句n;
default:语句n+1; // default语句可以省略
endcase
使用条件语句注意事项
在使用条件语句时,应注意列出所有条件分支,否则,编译器认为条件不满足时,会引进一个触发器保持原值。这可用于设计时序电路,例如在计数器的设计中,条件满足则加1,否则保持不变;而在组合电路设计中,应避免这种隐含触发器的存在。
为避免偶然生成锁存器的错误。如果用到if语句,最好写上else项。如果用case语句,最好写上default项。遵循上面两条原则,就可以避免发生这种错误。
循环语句
for语句
for(循环变量赋初值;循环结束条件; 循环变量增值) 执行语句;
先给控制循环次数的变量赋初值。再判定控制循环的表达式的值, 如为假则跳出循环语句,如为真则执行指定的语句后,执行一条赋值语句来修正控制循环变量次数的变量的值,然后再次判断。
repeat语句
repeat(循环次数表达式) 语句;
// or
repeat(循环次数表达式)begin……end;
连续执行一条语句或者一个语句块 n 次。
while语句
while(循环执行条件表达式) 语句;
// or
while(循环执行条件表达式) begin……end;
执行一条语句直到某个条件不满足。如果一开始条件即不满足(为假),则语句一次也不能被执行。
forever语句
forever 语句;
// or
forever begin……end;
forever循环语句连续不断地执行后面的语句或语句块,常用来产生周期性的波形,作为仿真激励信号。它与always语句的不同之处在于它一般用在initial语句块中。若要用它进行模块描述,可用disable语句进行中断。
结构说明语句
在一个模块(module)中,使用initial和always语句的次数是不受限制的。initial说明语句一般用于仿真中的初始化,仅执行一次;always块内的语句则是不断重复执行的。task和function语句可以在程序模块中的一处或多处调用。这些语句为不可综合语句
initial语句
initial <语句>。initial块常用于测试文件和虚拟模块的编写,用来产生仿真测试信号和设置信号记录等仿真环境。如:
initial begin //在仿真开始前对各个变量进行初始化
areg=0; //初始化寄存器areg
for(index=0;index<size;index=index+1)
memory[index]=0; //初始化一个memory
end
always语句
always <时序控制> <语句>。沿触发的always块常常描述时序逻辑, 如果符合可综合风格要求可用综合工具自动转换为表示时序逻辑的寄存器组和门级逻辑,而电平触发的always块常常用来描述组合逻辑和带锁存器的组合逻辑,如果符合可综合风格要求可转换为表示组合逻辑的门级逻辑或带锁存器的组合逻辑。如:
reg[7:0] counter;
reg tick;
always @(posedge areg) begin //每当areg信号的上升沿出现时
tick = ~tick; //把tick信号反相
counter = counter + 1; //并且把counter增加1
end
task语句
task和function说明语句分别用来定义任务和函数。利用任务和函数可以把一个很大的程序模块分解成许多较小的任务和函数便于理解和调试。
任务调用变量和定义时说明的I/O变量是一一对应的。调用任务test时,端口的值按照顺序赋值给输入输出端口。变量data1和data2的值赋给in1和in2,而任务完成后输出通过out1和out2赋给了code1和code2。
task test; //任务名test
input in1,in2; //端口及数据类型声明语句
output out1,out2;
out1 = in1 & in2; //其他语句
out2 = in1 | in2;
endtask//任务定义结束
test(data1,data2,code1,code2); //任务的调用
需要注意:1.任务的定义与调用须在一个module模块内。2.定义任务时,没有端口名列表,但需要在后面进行端口和数据类型的说明。3.当任务被调用时,任务被激活。任务的调用与模块调用一样通过任务名调用实现,调用时,需列出端口名列表,端口名的排序和类型必须与任务定义中的排序和类型一致。4.一个任务可以调用别的任务和函数,可以调用的任务和函数个数不限。
function语句
函数的定义中蕴含了一个与函数同名的、函数内部的寄存器。在函数定义时,将函数返值所使用的寄存器设为与函数同名的内部变量,因此函数名被赋予的值就是函数的返回值。例子中,gefun最终赋予的值即为函数的返回值。
/*gefun函数循环核对输入的每一位,计算出0的个数,并返回一个适当的值*/
function [7:0] gefun; //<返回值位宽或类型说明> 函数名
input[7:0] x; //端口声明
reg [7:0] count = 0 //局部变量声明
integer i;
for (i = 0;i <=7;i = i + 1)//其他语句
if(x[i] == 1'b0) count = count + 1;
gefun = count;
endfunction//函数定义结束
assign out = is_legal ? gefun(in) : 1'b0; //函数调用<函数名>(<表达式>)
需要注意:
- 函数的定义不能包含有任何的时间控制语句,即任何用#、@、或wait来标识的语句。
- 函数不能启动任务。
- 定义函数时至少要有一个输入参量。
- 在函数的定义中必须有一条赋值语句给函数中的一个内部变量赋以函数的结果值,该内部变量具有和函数名相同的名字。
IP例化语句
当我们在调用别人已经写好的IP核,或者使用自己的IP核时,需要对IP核进行元件例化操作
例化的目的是在上一级模块中调用例化的模块完成代码功能,在 Verilog 里例化信号的格式如下:模块名必须和要例化的模块名一致,包括模块信号名也必须一致。连接信号为 TOP 程序跟模块之间传递的信号,模块与模块之间的连接信号不能相互冲突,否则会产生编译错误。
实际使用中,会有两种例化形式,具体格式如下:
//按信号位置例化(不推荐)
mudule_name new_module_name(new_signal_1,new_signal_2,new_signal_3);
//按信号名称例化(推荐)
mudule_name new_module_name
(
.signal_1 (new_signal_1),
.signal_2 (new_signal_2),
.signal_3 (new_signal_3)
);
在一个模块中如果有定义参数,而我们在调用该IP核时,想向其内部传递参数,可在在 module 后用#()进行传递,具体格式如下
被调用的功能模块
module rom
#(
parameter depth =15,
parameter width = 8
) (
input [depth-1:0] addr ,
input [width-1:0] data ,
output result
) ;
/////功能代码部分,此处省略不写////
endmodule
顶层调用模块模块
module top() ;
wire [31:0] addr ;
wire [15:0] data ;
wire result ;
rom
#(
.depth(32),
.width(16)
)
r1(
.addr(addr) ,
.data(data) ,
.result(result)
) ;
endmodule
生成语句
Verilog中的生成语句主要使用generate语法关键字,按照形式主要分为循环生成与条件生成。
循环生成语句
循环生成的主要目的是简化我们的代码书写,利用循环生成语句我们可以将之前需要写很多条比较相似的语句才能实现的功能用很简短的循环生成语句来代替。
generate-for语句基本语法如下:
generate
genvar <var1>;
for (<var1> = 0 ; <var1> < num ; <var1>=<var1>+1)
begin: <label_1>
<code>;
end
endgenerate
关于以上语法有几点注意:
- 循环生成中for语句使用的变量必须用genvar关键字定义,genvar关键字可以写在generate语句外面,也可以写在generate语句里面,只要先于for语句声明即可;
- 必须给循环段起一个名字。这是一个强制规定,并且也是利用循环生成语句生成多个实例的时候分配名字所必须的;
- for语句的内容必须加begin-end,即使只有一条语句也不能省略。这也是一个强制规定,而且给循环起名字也离不开begin关键字;
- 可以是实例化语句也可以是连续赋值语句。
具体举例如下:
input [3:0] a,b;
output [3:0] c,d;
generate
genvar i;
for (i=0; i < 4; i=i+1)
begin : genExample
myAnd insAnd (.a(a[i]), .b(b[i]), .c(c[i]));
assign d[i] = a[i];
end
endgenerate
上述实例化展开来类似:
myAnd genExample(0).insAnd (.a(a[0]), .b(b[0]), .c(c[0]));
myAnd genExample(1).insAnd (.a(a[1]), .b(b[1]), .c(c[1]));
myAnd genExample(2).insAnd (.a(a[2]), .b(b[2]), .c(c[2]));
myAnd genExample(3).insAnd (.a(a[3]), .b(b[3]), .c(c[3]));
条件生成语句
条件生成的目的是为了左右编译器的行为,类似于C语言中的条件选择宏定义,根据一些初始参数来决定载入哪部分代码来进行编译。Verilog中共提供了两种条件生成语句,一种是generate-if语句,一种是generate-case语句,两者的功能几乎相同,只是书写形式不一样而已.
generate-if语句
基本语法如下:
generate
if (<condition>) begin: <label_1>
<code>;
end
else if (<condition>) begin: <label_2>
<code>;
end
else begin: <label_3>
<code>;
end
endgenerate
关于以上语法有三点注意:必须是常量比较,例如一些参数,这样编译器才可以在编译前确定需要使用的代码;if语句的内容中,begin-end只有在 < code > 有多条语句时才是必须的;每一个条件分支的名称是可选的,这点不像循环生成语句那么严格。
具体举例如下:
wire c, d0, d1, d2;
parameter sel = 1;
generate
if (sel == 0)
assign c = d0;
else if (sel == 1)
assign c = d1;
else
assign c = d2;
endgenerate
该例子表示编译器会根据参数sel的值,来确定到底是让d0~d2中哪个变量和c连通。但是注意,一旦连通,那么要想更改必须修改参数后重新编译。
generate-case语句
基本语法如下:
generate
case (<constant_expression>)
<value>: begin: <label_1>
<code>
end
<value>: begin: <label_2>
<code>
end
……
default: begin: <label_N>
<code>
end
endcase
endgenerate
关于以上语法有三点注意,和generate-if类似:
<constant_expression>必须是常量比较,例如一些参数,这样编译器才可以在编译前确定需要使用的代码;
case语句的内容中,begin-end只有在< code >有多条语句时才是必须的;
每一个条件分支的名称是可选的,这点不像循环生成语句那么严格。
具体举例如下:
wire c, d0, d1, d2;
parameter sel = 1;
generate
case (sel)
0 :
assign c = d0;
1:
assign c = d1;
default:
assign c = d2;
endcase
endgenerate
该例所描述的功能和generate-if小节的例子是一模一样的。
编译预处理语句
预处理命令以符号“`”开头,以区别于其他语句。在编译时,通常先对这些特殊语句进行“预处理”,然后再将预处理的结果和源程序一起进行编译。
`define语句
`define 语句用来将一个简单的名字或标志符(或称宏名)来代表一个复杂的名字或字符串,其一般形式为:"`define 标志符(宏名) 字符串"
`define IN ina + inb + inc + ind //用宏名IN来代替表达式ina + inb + inc + ind
`define WORDSIZE 8
reg [`WORDSIZE:1] data; // 相当于定义reg[8:0] data
`define用于将一个简单的宏名来代替一个字符串或一个复杂的表达式。
宏定义语句行末不加分号,这一点尤其要注意。
在引用已定义的宏名时,不要忘了在宏名的前面加上符号“`”,以表示该名字是一个宏定义的名字。
采用宏定义,可以简化程序的书写,而且便于修改。若需要改变某个变量,只须改变`define定义行,一改全改。比如在上面的例子中,定义data是一个8位的寄存器变量,若要将其改为16位,只须将定义行改为“`defineWORDSIZE 16”即可。
`include语句
`include是文件包含语句,它可将一个文件全部包含到另一个文件中。其一般形式为:`include 文件名
`include "adder.v" //包含一个名为adder.v的文件
一个`include语句只能指定一个被包含的文件。
`include语句可以出现在源程序的任何地方。被包含的文件若与包含文件不在同一个子目录下,必须指明其路径。
文件包含允许多重包含,比如文件1包含文件2,文件2又包含文件3等。
`timescale语句
`timescale语句用于定义模块的时间单位和时间精度,其使用格式如下:"`timescale <时间单位> / <时间精度>"
`timescale 10ns/1ns //本模块的时间单位是10ns,时间精度为1ns
reg sel;
initial begin
#10 sel = 0; //在10ns*10时刻,sel变量被赋值为0
#10 sel = 1; //在10ns*20时刻,sel变量被赋值为1
end
其中用来表示时间度量的符号有:s、ms、us、ns、ps和fs.
`ifdef、`else、`endif
有时希望对其中的一部分内容只有
在满足条件才进行编译,也就是对一部分内容指定编译的条件,这就是“条件编译”。有时,希望当
满足条件时对一组语句进行编译,而当条件不满足是则编译另一部分。格式如下:
`ifdef 宏名 (标识符)
程序段1
`else
程序段2
`endif
不同抽象级别的Verilog模型
Verilog HDL是一种能够在多个级别对数字电路和数字系统进行描述的高级语言,Verilog HDL模型可以是对实际电路的不同级别的抽象。这些抽象级别一般可分为5级:
- 系统级(System Level)
- 算法级(Algorithm Level)
- 寄存器传输级(RTL,Register Transfer Level)
- 门级(Gate Level)
- 开关级(Switch Level)
其中,前三种属于高级别的描述方法,又称为行为级描述。门级模型是描述逻辑门以及逻辑门之间连接关系的模型。而开关级的模型则是描述器件中三极管和存储节点以及它们之间连接关系的模型。Verilog HDL在开关级提供了一整套完整的组合型原语(primitive),可以精确地建立MOS器件的底层模型。
门级描述
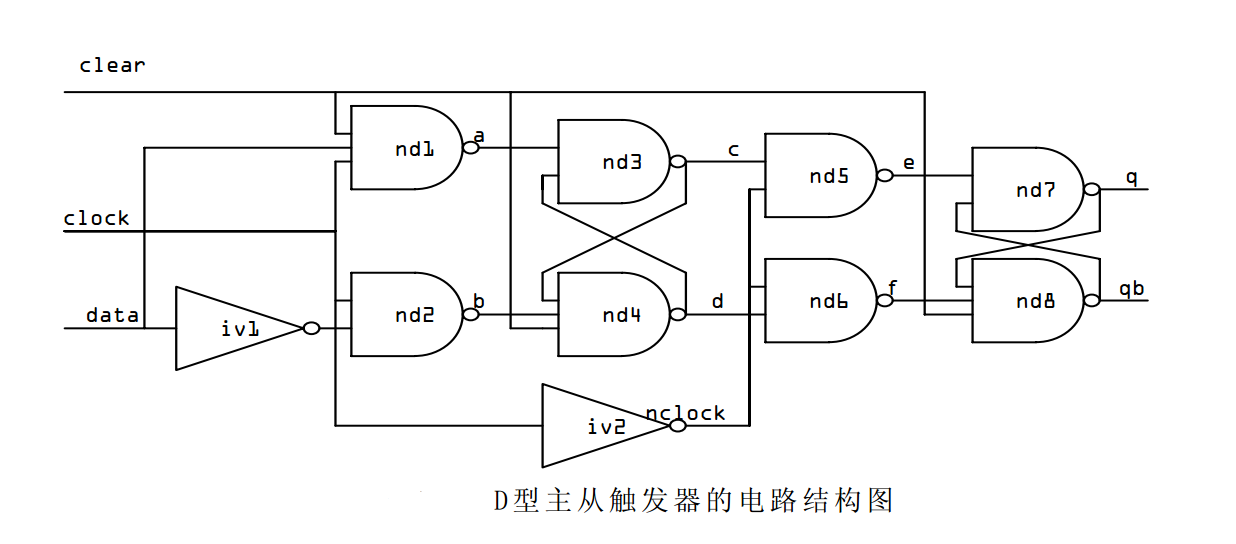
Verilog HDL有关门类型的关键字共有26个,比较常用的有下面几个:not:非门;and:与门;nand:与非门;or:或门;nor:或非门;xor:异或门;xnor:异或非门(同或门);buf:缓冲器;bufif1,bufif0,notif1,notif0:各种三态门。
module flop(data,clock,clear,q,qb);
input data,clock,clear;
output q,qb;
nand #10 nd1(a,data,clock,clear),
nd2(b,ndata,clock),
nd4(d,c,b,clear),
nd5(e,c,nclock),
nd6(f,d,nclock),
nd8(qb,q,f,clear);
nand #9 nd3(c,a,d),
nd7(q,e,qb);
not #10 iv1(ndata,data),
iv2(nclock,clock);
endmodule
生成的电路
行为级(RTL)描述
一般的Verilog HDL设计中,很少采用门级描述,而使用较多的是行为级描述。对于设计者而言,采用的描述级别越高,设计越容易。
module gen_clk (
output clk,
output reset
);
reg clk, reset;
initial begin
reset = 1; //初始状态
clk=0;
#3 reset = 0;
#5 reset = 1;
end
always #5 clk = ~clk; //每隔5个单位时间翻转一次
endmodul
可以看出,行为级描述能够更加直观的看出所设计的逻辑功能,但需要使用综合器将代码转换为电路逻辑。
组合逻辑设计
常见的组合逻辑设计
二选一多路选择器
写法1(与或非运算):
module mux2_1(a,b,s,y); //mux2_1是器件的名称
input a,b,s; //输入接口a,b,s
output y; //输出接口y
assign y = (a& (~s)) | (b&s); //通过与或非门实现逻辑功能
endmodule
写法2(门级描述):
module mux2_1(a,b,s,y); //mux2_1是器件的名称
input a,b,s; //输入接口a,b,s
output y; //输出接口y
wire ns,as,bs;
not(ns,s);
and(as,a,ns);
and(bs,b,s);
or(y,as,bs);
endmodule
写法3(RTL):
module mux2_1(a,b,s,y); //mux2_1是器件的名称
input a,b,s; //输入接口a,b,s
output y; //输出接口y
assign y = (s ==0) ? a:b; //s等于0,输出a,反之,输出b
endmodule
全加器
可先实现一个半加器,再通过顶层文件镜像元件例化实现全加器。
先编写一个半加器模块:
module half_adder(a,b,so,co); //编写半加器模块
input a,b;
output so,co;
assign so = a ^ b;
assign co = a & b;
endmodule
再通过原件例化实现全加器:
module adder_top (a,b,ci,so,co)
input a,b,ci;
output so,co;
wire c1,c2,s1;
half_adder u1( //元件例化一个半加器处理ab求和
.a (a),
.b (b),
.so (s1),
.co (c1)
);
half_adder u2( //原件例化一个全加器处理进位
.a (s1),
.b (ci),
.so (so),
.co (c2)
);
assign co = c1|c2;
endmodule
42编码器设计
写法1(case语句):
module encoder(a0,a1,a2,a3,y0,y1); //定义编码器模块,输入为a输出为b
input a0,a1,a2,a3;
output y0,y1;
wire [3:0] a;
reg [1:0] y;
assign a = {a3,a2,a1,a0} //将输入的a3至a0进行位拼接操作
assign y0 = y[0]; //将寄存器的y值进行输出
assign y1 = y[1];
always @(a) begin
case(a)
4'b0001 : y = 2'b00; //当输入是0001时,编码输出00
4'b0010 : y = 2'b01;//当输入是0010时,编码输出01
4'b0100 : y = 2'b10;//当输入是0100时,编码输出10
4'b1000 : y = 2'b11;//当输入是1000时,编码输出11
default :y = 2'bxx;
endcase
end
endmodule
写法2(if语句):
module encoder(a0,a1,a2,a3,y0,y1); //定义编码器模块,输入为a输出为b
input a0,a1,a2,a3;
output y0,y1;
reg [1:0] y;
assign y0 = y[0]; //将寄存器的y值进行输出
assign y1 = y[1];
always @(a0,a1,a2,a3) begin
if (a0) y = 2'b00; //使用if-else if-else语句对输入a进行分类
else if (a1) y = 2'b01;
else if (a2) y = 2'b10;
else y = 2'b11;
end
endmodule
38译码器
//38译码器
module threetoeight(addr,decode);
input [2:0] addr;
output reg [7:0] decode;
always @(addr)
begin
case(addr)
3'b000 : decode = 8'b111_111_10;
3'b001 : decode = 8'b111_111_01;
3'b010 : decode = 8'b111_110_11;
3'b011 : decode = 8'b111_101_11;
3'b100 : decode = 8'b111_011_11;
3'b101 : decode = 8'b110_111_11;
3'b110 : decode = 8'b101_111_11;
3'b111 : decode = 8'b011_111_11;
endcase
end
endmodule
时序逻辑设计
Verilog HDL语言中触发器的生成:首先需要定义一个reg型的变量,而这个变量的名字可以是输出端,也可以是内部信号。通过一个always语句块来描述电路的时序行为,这里的always语句块的敏感信号是边沿敏感的,程序中的clk是一个上升沿敏感信号,每次clk信号的一个上升沿到来时,都将触发always语句块的一次执行。
敏感信号类型以及同步、异步操作:使用posedge和negedge关键字来描述一个边沿敏感型信号,分别表示上升沿(positive edge)和下降沿(negative edge)。posedge和negedge关键字除了用于描边沿敏感型信号以外,还可以用在异步事件的描述中,这时posedge一般表示一个异步事件在信号高电平时有效,而negedge则表示异步事件在信号低电平时有效。异步操作控制信号出现在敏感信号列表里面,这时是异步操作;否则为同步操作。
D触发器设计
module d_flip_flop(d,clk,q);
input d,clk;
output q;
reg q;
always @(posedge clk) q<=d; //当上升沿到来时,将d的值赋值给q
endmodule
带有异步清零和异步复位的D触发器
module d_flip_flop(aclr,aset,d,ck,q);
input aclr,aset,d,ck;
output q;
reg q;
/*当任何一个信号发生变化时,均会在同一时刻改变输出,不与时钟同步,故称异步复位*/
always @(posedge aclr or posedge asset or posedge ck) begin
if(aclr) q <=1'b1;
else if(aset) q<=1'b1;
else q<=d;
end
endmodule
带有同步清零和同步置位的D触发器
module d_flip_flop(aclr,aset,d,ck,q);
input aclr,aset,d,ck;
output q;
reg q;
/*只有当时钟上升沿到来时,才对输出q进行改变,复位和清零操作与时间同步,故称同步复位*/
always @(posedge ck) begin
if(aclr) q <=1'b1;
else if(aset) q<=1'b1;
else q<=d;
end
endmodule
https://zhenhuizhang.tk/
若需要md版本或者pdf版本,请邮件联系邮箱。
本网站文章版权均为本人所有,未经同意不得私自搬运复制,欢迎注明引用出处的合理转载,图片转载请留言。文章内容仅用于技术研究和探索,不得用于违法目的。